Optimal viktning av väderprognoser
Klicka på  ovanför ”Selections” och klicka igen på
längst nere till vänster i den
dialogruta som kommer upp. Välj ”Automatic”. Då förändras beteendet för gridet
överst. Istället för att mata in tal i varje cell kan man markera cellerna. En
markerad cell innebär att för aktuell prognoshorisont ska den motsvarande valda
prognosen ingå som förklarande variabel i regressionen. I exemplet nedan kommer
två regressioner att beräknas, dels för intervallet 13-24 timmar, dels för 25-36
timmar framåt. Båda dessa kommer att ta in ”DMU Corr”, ”DMU High” och
”WeatherTech” som förklarande variabler. Programmet kommer automatiskt att fylla
i vikter för de prognoshorisonter som ej är valda så att de uträknade vikterna
för rad tre kommer att kopieras till rad ett och två. Likaså, ifall denna
viktning ska utvärderas för mer än 36 timmar framåt så kommer ”25-36”-timmars
viktningen att användas. Dessa beräkningar är tidskrävande och det kan finnas
behov av att begränsa antalet regressioner till de prognoshorisonter som man har
störst behov av att minimera balansfelen på.
ovanför ”Selections” och klicka igen på
längst nere till vänster i den
dialogruta som kommer upp. Välj ”Automatic”. Då förändras beteendet för gridet
överst. Istället för att mata in tal i varje cell kan man markera cellerna. En
markerad cell innebär att för aktuell prognoshorisont ska den motsvarande valda
prognosen ingå som förklarande variabel i regressionen. I exemplet nedan kommer
två regressioner att beräknas, dels för intervallet 13-24 timmar, dels för 25-36
timmar framåt. Båda dessa kommer att ta in ”DMU Corr”, ”DMU High” och
”WeatherTech” som förklarande variabler. Programmet kommer automatiskt att fylla
i vikter för de prognoshorisonter som ej är valda så att de uträknade vikterna
för rad tre kommer att kopieras till rad ett och två. Likaså, ifall denna
viktning ska utvärderas för mer än 36 timmar framåt så kommer ”25-36”-timmars
viktningen att användas. Dessa beräkningar är tidskrävande och det kan finnas
behov av att begränsa antalet regressioner till de prognoshorisonter som man har
störst behov av att minimera balansfelen på.
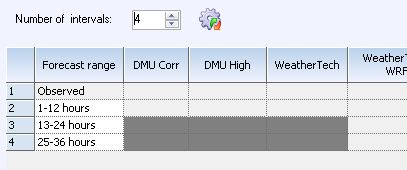
När man ändrar viktningen från ”Manual” till ”Automatic”
kommer en rad valmöjligheter att dyka upp i dialogrutan. Den stegvisa
regressionen ger en möjlighet att sortera bort väderprognoser som inte bidrar
tillräckligt mycket till att förklara utfallet utan kan sorteras bort helt och
hållet. Detta går till så att den stegvisa regressions-algoritm som används
identifierar den prognos som ensam kan förklara så mycket av lastens variation
som möjligt.
Därefter letas efter den av de återstående som ensam kan
beskriva mest av den lastvariation som återstår.
I ett tredje steg letas så efter den återstående prognos
som bäst förklarar vad som nu återstår att förklara av lasten, o.s.v.
Efter ett antal steg så kommer inklusionen av en ny prognos
att endast marginellt förbättra resultatet och denna förbättring kan vara rent
slumpmässigt betingad av förhållanden under utvärderingsperioden.
För att avbryta den stegvisa proceduren används ett s.k.
signifikanstest (F-test). Varje statistiskt test är dock förenat med viss
osäkerhet och du måste bestämma dig för vilken risk du är beredd att ta i
signifikanstesten.
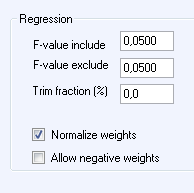
I rutan ”Regression” kan man ange:
•
F-value include: Ange den risk du är beredd att ta för att
testen skall acceptera inkluderingen av en ny variabel trots att den inte bör
finnas med. Om du vill att den inte skall ta fel oftare än i 5% av fallen så
anger du 0,05 under rubriken ”F-value include”.
•
F-value exclude: Den stegvisa algoritmen har också möjligheter att
kasta ut en variabel som var viktig i ett tidigare steg men som inte längre är
viktig när ytterligare en eller flera variabler tillkommit. Den risk du vill ta
för att metoden behåller en felaktig variabel trots att den borde kastas ut
anger du under rubriken: ”F-value exclude”. Ett högre värde än
”F-value include” kommer att ge en konservativ modell som i regel inte kastar ut
variabler som redan har tagits med.
•
Trim fraction: Hur stor andel av extremvärdena ska undantas från
regressionen. Hela intervallet mellan utvärderingsperiodens prognosticerade
minimivärde och maximivärde delas in i ett antal delinterval. För varje
delinterval plockas de högsta och lägsta uppmätta värdena bort från
regressionen. Ett högt värde ger regressioner som tenderar att minimera felen
med tonvikten på ett lågt medelabsolutfel (MAE) i kontrast till en ordinär
regression (värdet 0) som minimerar RMSE.
•
Normalize weights: Resultatet av en regression ger normalt dels en
summa av vikterna som är skild från 100% dels en konstant-term skild från noll.
Detta kan vara befogat då prognoserna för en viss prognoshorisont systematiskt
kan avvika från det observerade vädret som prognosmodellerna är tränade på. Om
man istället vill att resultatet ska spegla ett ”förtroende” man för de olika
väderprognoserna kan man bocka för denna kryssruta. Då kommer vikternas summa
skalas upp till 100% och konstanten tas bort.
•
Allow negative weights: Den linjära regressionen kan även
resultera i negativa vikter. Kryssa ur denna om det inte ska tillåtas.
I rutan ”Tolerance” finns möjligheter att göra
inställningar för varningsmeddelanden från regressionsprocessen. I normalfallet
bör resultatet från regressionen ge positiva vikter (möjligen även någon
liten negativ) vars summa ligger nära 1. Även konstanten borde vara liten i
förhållande till medellasten. Avvikelser från detta kan tyda på problem
någonstans i prognosprocesserna.
•
Max sum of abs weights: Om man tillåter negativa vikter kan
absolutbeloppet av enskilda vikter bli betydligt högre än 100% även om summan av
vikterna ligger nära 100%. Exempelvis kan en regression lägga 200% vikt på
prognos 1 och -100% på prognos 2. Ställ in den högsta accepterade summan av
absolutbeloppen av vikterna.
•
Min sum of weights: Programmet skickar en varning ifall summan av
vikterna understiger detta värde.
•
Max constant absolute value: Programmet skickar en varning om
absolutvärdet av den under regressionen skattade konstanten överstiger det
angivna procent-värdet (procent av medellasten under utvärderingsperioden)
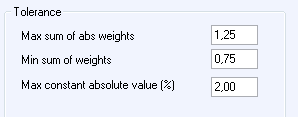
När man blivit nöjd med inställningarna sparar man dessa
som en ”Selection” som man sedan utvärderar. Under utvärderingen kommer man då
först räkna ut de optimala vikterna för alla prognosserier till alla serier man
kryssat i. I steg två kommer dessa sedan att utvärderas för de
prognoshorisonter man angivit i ett ”utdrag (extract)”.